Many of us site managers and tech Seo will have thought about using the sitesearch link box in Google results. When Google displays expanded results with sub-results, they offer to integrate a sitesearch box. Posts on this are rare, and have little info on the impact of these. What I have seen so far indicates that there's no significant impact on natural search traffic. Information about on site conversion (closer match should increase on-site conversion) is not published to my knowledge, and would be hard to separate out from the overall search.
There are three options to deal with this Google offer:
1. ignore, do nothing
2. block the searchbox actively
3. integrate schema into the homepage of the site to 'invite' Google to add the box.
Which route to go? A first step, as often, is to look at how common it is to use one of these options. Working on one of the largest websites, I compare here with the top 10,000 sites by traffic as estimated by Alexa (top million sites report).
Now showing:
- how many block, use schema, do nothing,
- average rank of blocked sites compared to sites with schema
- what do the top sites do (surprise)
- top sites blocked by rank
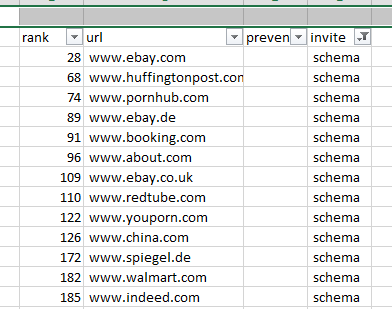
- top sites with schema by rank
- bash script to test
1. How many block, use schema, do nothing

2. Average rank of blocked sites compared to sites with schema

3. What do the top sites do (surprise)

4. Top sites blocked by rank

5. Top sites with schema by rank
6. Bash script to test
while read -r line; do
if [[ $line != www* ]]; then
line="www.${line}"
fi
output=$(curl -s "${line}" )
nobox=$(echo "$output" | grep "nosite")
boxschema=$( echo "$output" | grep "SearchAction")
if [[ $nobox != "" ]] ; then
nobox="blocked"
fi
if [[ $boxschema != "" ]] ; then
boxschema="schema"
fi
echo -e "$line \t $nobox \t $boxschema" | tee -a nobox-or-box.txt
done < $1
