Some time ago, I think it was April, Google announced they would serve web pages that are too slow for some users scrape off the owner website and serve from their servers. The test was supposed to start in Indonesia and targeted towards 2G connection. Then later, they started rolling this out for 'select countries' and slow mobile connections (2G).
The 'transcoding' is done on the fly, according to news, and speeds things significantly up, we have seen 10x faster loads.
Weblight - look and feel
This is how it looks like in the original on the left, and the 'scraped' site on the right. Not bad, really. Users can load the original page in the top section, with a warning that it might be slow. Sounds very user friendly approach to me. The navigation (nav icon in the upper left) is solid, and not missing anything in the top level.

Biggest flaw is that it removes pretty much all third party elements - including our tracking elements, scripts, etc.. Google claims to leave up to two ads on the page, and allow simple tracking with Google analytics.
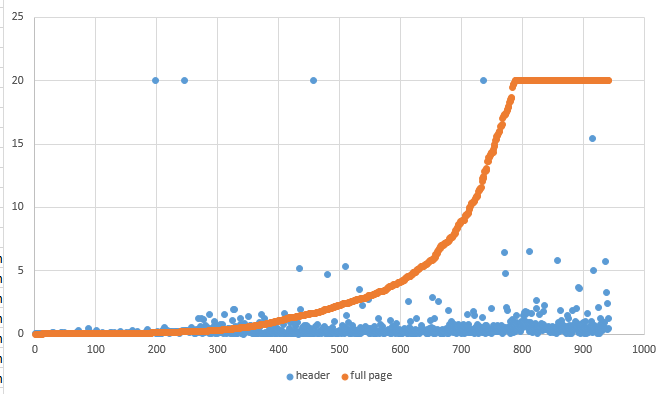
Traffic on weblight
We (Dell.com) actually see some traffic with Googleweblight. It is minuscule, noticed only because we have been specifically looking for it, but there it is. We see some referral traffic in Adobe sitecatalyst, and we also see the 'scraping' of pages in our logfiles.
Most of the traffic for us seems to be from India, and trying to reach a variety of pages in several countries instead just India, which might explain some of the slowness.
The scraped or 'transcoded' pages can be found in logs with cs_User_Agent="*googleweblight*", and the pages that get the referrer traffic from the referrer "googleweblight.com".
How relevant are 2G networks for global ecommerce
So far, it seems super small, but the market potential is quite big. Global data on network coverage is a bit harder to come by, but there are some relevant sources.Some excerpts from a McKinsey report:
"In developed countries and many developing nations, 2G networks are widely available; in fact, Ericsson estimates that more than 85 percent of the world’s population is covered by a 2G signal.42 Germany, Italy, and Spain boast 2G networks that reach 100 percent of the population, while the United States, Sri Lanka, Egypt, Turkey, Thailand, and Bangladesh have each attained 2G coverage for more than 98 percent of the population.43 Some developing markets don’t fare as well: as of 2012, 2G network coverage extended to 90 percent of the population of India, 55 percent of Ethiopia, 80 percent of Tanzania, and just under 60 percent of Colombia.44 Growing demand and accelerated rates of smartphone adoption in many markets have spurred mobile network operators to invest in 3G networks.
Ericsson estimates that 60 percent of the world population now lives within coverage of a 3G network. The level of 3G infrastructure by country reveals a stark contrast between countries with robust 3G networks and extensive coverage, such as the United States (95 percent), Western European nations (ranging from 88 to 98 percent), and Vietnam (94 percent), and many developing markets such as India, which are still in the early stages of deploying 3G networks."
(highlights by me)
The graph from the same publication shows significant 2G/3G only coverage even for the US.
Slightly more optimistic statistics from the ICT figures report for 2015 - look at US penetration rate for example, or Norway. A map and discussion with US internet speeds on Gizmodo.
How to see your site on Google weblight
For this blog, it is: googleweblight.com/?lite_url=https://andreas-wpv.blogspot.com . Don't forget to use some kind of mobile emulator, to see how it really looks like! Only some resolutions are supported - one is the standard Iphone 4 with 320 x 480.Google original:
- "If you have a Google account:
- Otherwise:
- On your mobile device, browse to the link
http://googleweblight.com/?lite_url=[your_website_URL]where the url is fully qualified (http://www.example.com).
OR - On your desktop, open the Chrome device mode emulator with the link
http://googleweblight.com/?lite_url=[your_website_URL]where the url is fully qualified (http://www.example.com) "
- On your mobile device, browse to the link
Is this legal? How about copyright?
Honestly - I don't want to go there, I am no lawyer, and there are some complex questions arising - internally.Google claims that companies win so much traffic, it is really in their best interest. For every site that does not want this treatment, there is a way to opt out described on the Google help pages, and it gives some insight into what's removed. Some more tech details on this article: mostly compression, removal of third party elements, reduction of design elements.
Google names this 'transcoding' - to me it looks like scraping and serving from their website, something that might be considered a copyright violation, and would likely be against Google 'terms of service' (highlights by me):
"Do not misuse our Services, for example, do not interfere with our Services or try to access them using a method other than the interface and the instructions that we provide. You may use our Services only as permitted by law, including applicable export and control laws and regulations. We may suspend or stop providing our Services to you if you do not comply with our terms or policies or if we are investigating suspected misconduct."
Additionally - would not adwords on a weblight page violate Adwords terms of service?
" Content that is replicated from another source without adding value in the form of original content or additional functionality
I would understand - perhaps misunderstand - this the way that Google Adwords cannot be used on weblight pages.
More general, is this scraping ok for Google to do?
Sept. 25, 2015: It seems from some glance in the detailed data transfer (chrome, fiddler), that it is more of a filtering of content with some kind of proxy. Working on it.
More general, is this scraping ok for Google to do?
Sept. 25, 2015: It seems from some glance in the detailed data transfer (chrome, fiddler), that it is more of a filtering of content with some kind of proxy. Working on it.
Resources:
Additionally to the above links, there are a few articles I found on this topic + Google sources:http://gadgets.ndtv.com/internet/news/google-india-to-offer-faster-access-to-mobile-webpages-for-android-users-702302
http://www.unrevealtech.com/2015/07/how-to-prevent-site-loading-google-weblight.html
http://www.androidauthority.com/google-web-light-looks-616450/
http://digitalperiod.com/google-web-light/
https://support.google.com/webmasters/answer/6211428?hl=en